
Everyone Measures AI Accuracy. We Measured What the Experts Did With It.
How SecurityPal evaluates every AI-generated security questionnaire response, and what our analysts revealed about the limits of accuracy alone.

Every AI-powered security questionnaire tool reports accuracy metrics, claiming 90-95% accuracy without showing the methodology behind the number.
We know because we report it too.
But after running AI-generated responses through certified human experts across enterprise customers, we stopped trusting that number. Not because it was wrong, but because it was hiding the things that actually mattered for our customers.
95% accuracy on a 200-question questionnaire means 10 wrong answers. That sounds manageable until you think about what those ten answers might say. One says, "Yes, we encrypt data at rest," when the vendor does not. Another says, "No, we have not experienced a security incident," when the vendor has. In compliance, these are not rounding errors. They are material misrepresentations.
When one wrong answer quickly becomes thirteen
The problem is not just wrong answers. It is a structural domino effect.
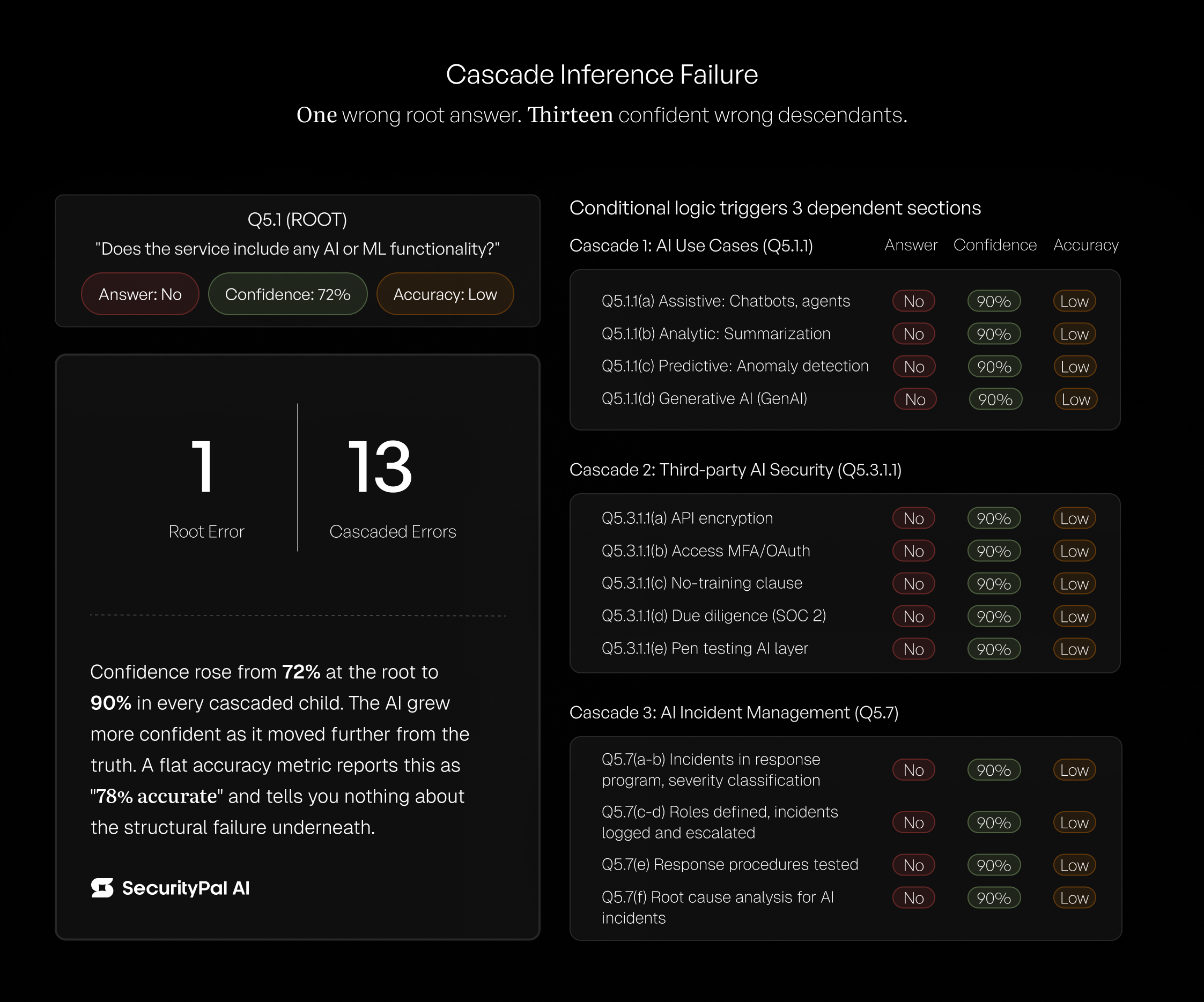
While evaluating an AI-completed questionnaire for a customer, our experts flagged a pattern that no accuracy metric would surface. The questionnaire asked: "Does the service include any AI or ML functionality?" The AI answered "No." The correct answer was "Yes." Confidence score: 72%.
The questionnaire's conditional logic triggered dependent questions:
- What AI use cases are implemented?
- What security controls protect AI integration?
- What incident response procedures exist for AI failures?
Because the root answer was "No," the AI answered "No" to all of them. Thirteen cascaded wrong answers flowing from one wrong AI-generated answer.
Those thirteen cascaded errors carried a confidence score of 90%, 18 points higher than the root error. The AI became more confident as it moved further from the truth.
Across the full questionnaire, the correlation between confidence scores and accuracy was 0.15 — effectively zero. Confidence, the second most popular quality metric after accuracy, was only noise.
We call this Cascade Inference Failure. A tool reporting 78% accuracy on this questionnaire would be telling you a true number that communicates nothing about the structural failure underneath. It was not a collection of independent mistakes. It was one mistake the AI confidently repeated thirteen times.
How do you measure AI success?
Accuracy is the standard way to evaluate AI. But if accuracy is measured from the AI's perspective, it produces a number that sounds reassuring and tells the buyer nothing about what will happen in production.
We asked a different question: what did experts do differently?
Did they ship it? Did they fix it? Did they discard it?
That decision, made by a domain expert under a real SLA for a real customer, is the most reliable quality signal in this domain. It cannot be gamed by prompt tuning. It cannot be inflated by testing on easy questions. It is the only true north for measuring the AI’s output efficiency.
This is the difference between using AI to do the job vs. getting the job done with the help of an integrated system where AI operates alongside expert human oversight, providing diagnostic depth where it matters.
We call this Hyper-Supervised Assurance Intelligence, or H_SAI.
We built a multi-layer evaluation framework around this principle, refined through months of production review. It captures structured diagnostic data as a natural byproduct of expert review — telling us not just that the AI was wrong, but why. It categorizes errors that map directly to engineering improvements, without creating a separate evaluation burden for our analysts.
What this means
The EU AI Act requires transparency about AI-generated content starting August 2026. The DOJ Cyber-Fraud Initiative creates enforcement risk for false cybersecurity claims. What the recent compliance scandal actually exposed is that this structural problem applies any time AI compliance output ships without structured expert verification.
McKinsey found that 74% of enterprises identify AI inaccuracy as a highly relevant risk, yet most report a meaningful gap between the risks they recognize and the controls they have in place. That gap will not close with better percentages. It will close when vendors provide verifiable evidence of how they measure quality.
We built our framework because the company handling enterprise compliance should be the most rigorous about measuring its own quality. We are preparing to publish empirical research based on production data collected through this framework. The findings go beyond what we have shared here.
If you are evaluating AI-powered security questionnaire tools, one question separates vendors who measure quality from vendors who claim it: How do you evaluate your AI’s output?
Research and analysis by SecurityPal's Data Science team: Anurodh Budathoki, Saugat Luitel, Nigam Niraula, Sweta Shrestha, and Ananta Upadhyaya with Habish Dhakal.










